デジタル機器の普及のともない、多様で膨大なデジタルデータがネットワーク上で生成されています。
このような膨大なデータ(ビッグデータ)は大きく2種類に分類されます。
| 構造化データ | 顧客情報(氏名、生年月日、住所等)、購入履歴、POSデータといった、 OracleやMySQLなどのデータベースで管理しやすいデータ |
| 非構造化データ | アクセスログ、音声、動画、ブログやSNS等の文字データ、各種センサーが発するデータ |
特に非構造化データは、今後急速に増加していくと推測されていますが、そのデータ量の多さから有効活用されていないのが現状です。
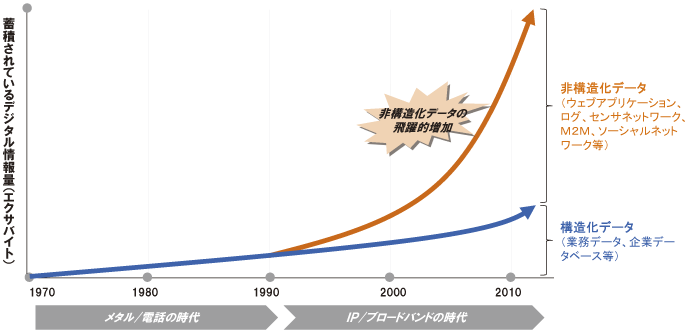
私たちは、Hadoopを基盤とし、非構造化データの蓄積と解析を行っています。
サービス概要
ひとくちに非構造化データといっても多岐にわたります。
私たちが中心に取り組んでいるのは 「波」 データの蓄積と解析です。
【対象データ例】
| ①医療系 | 心電図、酸素濃度、体温、呼吸数 等々 |
| ②物流・生産系 | 車両、生産機器等の各種センサーが発するログ、パルスデータ等 |
| ③環境系 | 地震データ、CO2、NOX、雨量、風圧、温度、放射線量等 |
これらのデータは逐次発生するため膨大な量となりますが、Hadoopを基盤とすることによりデータを安全に蓄積し、これを解析・可視化することにより、データの有効活用を図ることが可能となります。
解析イメージ
「波」データは大きく2つに分かれます。
1つは一定のパターンをもっているデータ、例えば心電図です。
もう1つは、酸素濃度、温度、株価など、パターンをもたないデータです。
私たちは、このような様々な波の特徴を分析できる解析エンジンを、Hadoop上に独自に構築することにより、多様な波の蓄積・解析を行い、新しい発見・研究に対する支援や、問題状況の自動検出・通知を行います。
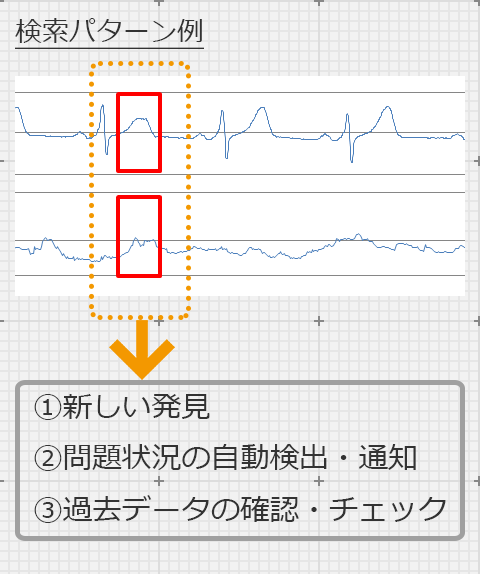
① パターンがあるデータの解析例
ここでは、ある被験者の心電図データから異常なデータを見つけ出す簡単な例を紹介します。
健常な被験者の心電図データを蓄積して分析した結果、以下のような心電図の基本波形パターンが得られたと仮定します。
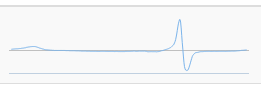
この基本波形パターンをある被験者の過去のデータから検索したところ、以下の図のようになりました。
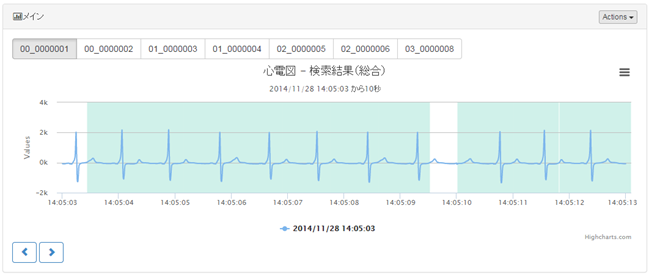
基本波形パターンに一致した所が緑色にハイライトされ、一致していない部分があることが分かります。この部分が異常の可能性があると考えることができます。
また同様に、病気を患っている人のデータから健常者には無いパターンが見つけ出せれば、病気の前兆の検知や、早期発見につなげることができるようになります。
② パターンが無いデータの解析例
パターンが無いデータとは、ここでは波の形が規則的ではないデータのことを言います。株価のチャートを例にしましょう。以下は、ある企業の株価チャートです。
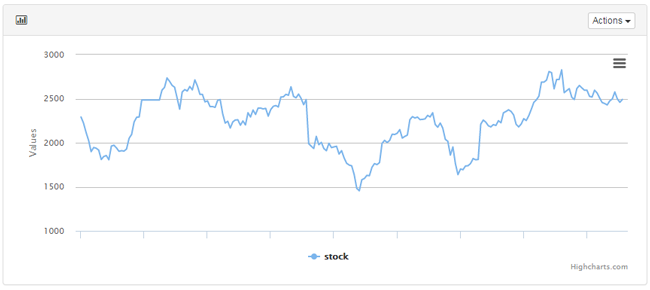
このチャートから、以下の3つの独自アルゴリズムによって特徴を検出します。
- 凹凸検出アルゴリズム
- 急変動検出アルゴリズム
- 範囲検出アルゴリズム
■凹凸検出アルゴリズム
データが上昇→下降または下降→上昇した部分、すなわち「上向きのコブ」や「下向きのコブ」のような形の部分で探します。
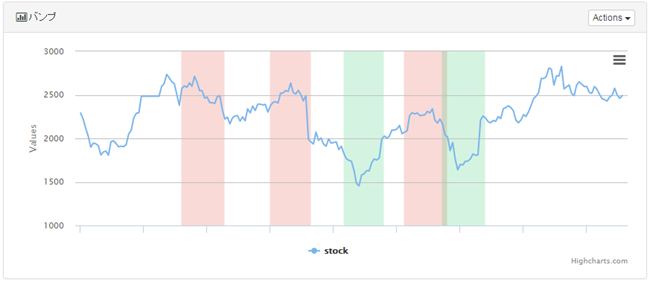
コブの上下の向き、広さ、深さは任意に設定でき、ここでは小さな幅は無視し、大きな幅を検出するようにしています。
■急変動検出アルゴリズム
データが急激に上昇または下降した部分を検出します。
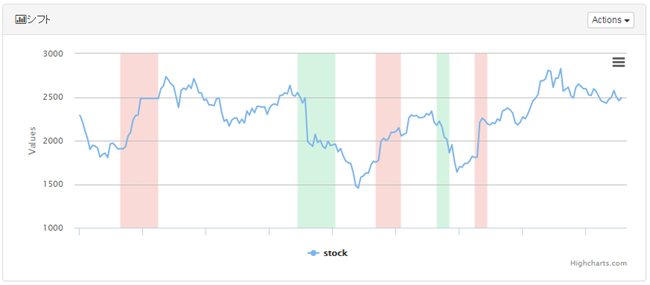
凹凸検出アルゴリズム同様、上昇・下降幅を任意に設定でき、ここでは小幅な上昇・下降は無視しています。
■範囲検出アルゴリズム
ある一定のYの範囲にデータが連続して存在した部分を検出します。
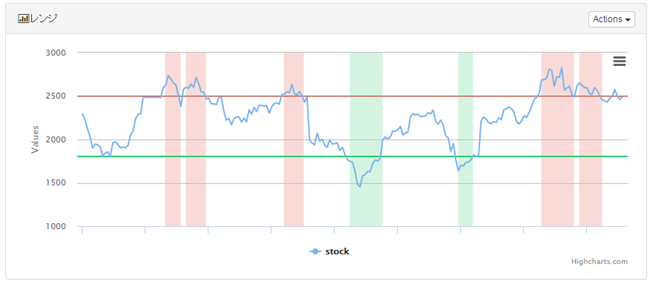
上記図の例では、Y軸の2500以上の範囲を赤、1800以下の範囲を緑で設定し、その範囲内にデータが一定期間連続して存在した部分を検出しています。
これらのアルゴリズムを組合せることにより、例えば健康な人と病気を患っている人とでは各種データでどのような特徴の違いがあるのかといった分析や、異常検知等が可能となります。
お問合せ
本サービス・ビッグデータの解析につきましては、こちらからお問い合わせください。
弊社ではこれら「波」のデータ以外にも、アクセスログやSNSから取得できるデータ等の非構造化データの解析はもちろんのこと、大規模データベース等の構造化データの解析も行っております。
「データからパターンを見つけて分析したい」「ログからユーザーの傾向を知りたい」「持っているデータを何か活用する方法はないか」など、お困りのことがありましたらお気軽にお問い合わせください。